both lda and pca are linear transformation techniquesgangster disciples atlanta
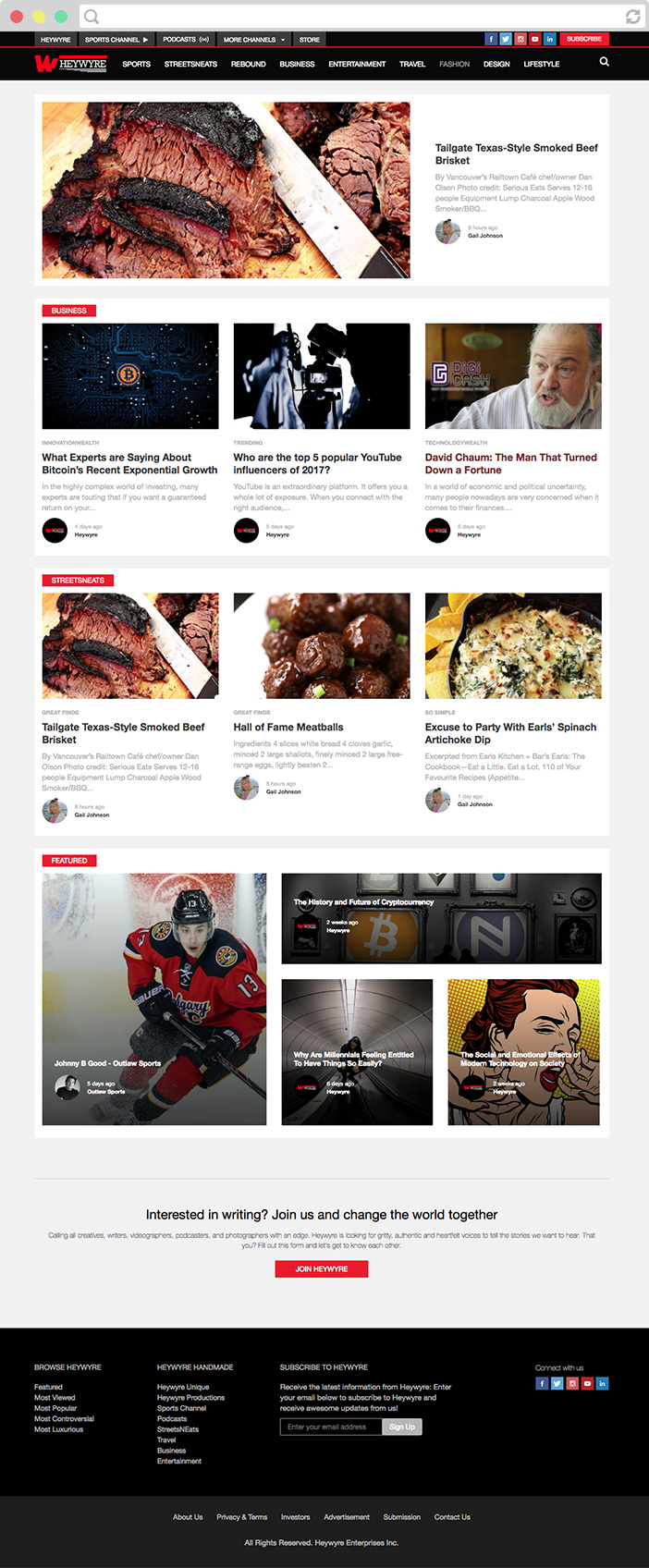
Our baseline performance will be based on a Random Forest Regression algorithm. for the vector a1 in the figure above its projection on EV2 is 0.8 a1. PCA LDA The performances of the classifiers were analyzed based on various accuracy-related metrics. Int. Linear discriminant analysis (LDA) is a supervised machine learning and linear algebra approach for dimensionality reduction. Additionally, there are 64 feature columns that correspond to the pixels of each sample image and the true outcome of the target. So, in this section we would build on the basics we have discussed till now and drill down further. J. Comput. Along with his current role, he has also been associated with many reputed research labs and universities where he contributes as visiting researcher and professor. So, something interesting happened with vectors C and D. Even with the new coordinates, the direction of these vectors remained the same and only their length changed. I hope you enjoyed taking the test and found the solutions helpful. To learn more, see our tips on writing great answers. Finally we execute the fit and transform methods to actually retrieve the linear discriminants. In the later part, in scatter matrix calculation, we would use this to convert a matrix to symmetrical one before deriving its Eigenvectors. PCA It searches for the directions that data have the largest variance 3. To better understand what the differences between these two algorithms are, well look at a practical example in Python. If the arteries get completely blocked, then it leads to a heart attack. https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47, https://en.wikipedia.org/wiki/Decision_tree, https://sebastianraschka.com/faq/docs/lda-vs-pca.html, Mythili, T., Mukherji, D., Padalia, N., Naidu, A.: A heart disease prediction model using SVM-decision trees-logistic regression (SDL). Also, checkout DATAFEST 2017. Whenever a linear transformation is made, it is just moving a vector in a coordinate system to a new coordinate system which is stretched/squished and/or rotated. What are the differences between PCA and LDA Complete Feature Selection Techniques 4 - 3 Dimension Similarly, most machine learning algorithms make assumptions about the linear separability of the data to converge perfectly. Both methods are used to reduce the number of features in a dataset while retaining as much information as possible. WebPCA versus LDA Aleix M. Martnez, Member, IEEE,and Let W represent the linear transformation that maps the original t-dimensional space onto a f-dimensional feature subspace where normally ft. This component is known as both principals and eigenvectors, and it represents a subset of the data that contains the majority of our data's information or variance. The performances of the classifiers were analyzed based on various accuracy-related metrics. Making statements based on opinion; back them up with references or personal experience. A popular way of solving this problem is by using dimensionality reduction algorithms namely, principal component analysis (PCA) and linear discriminant analysis (LDA). To have a better view, lets add the third component to our visualization: This creates a higher-dimensional plot that better shows us the positioning of our clusters and individual data points. Here lambda1 is called Eigen value. As you would have gauged from the description above, these are fundamental to dimensionality reduction and will be extensively used in this article going forward. LDA and PCA Eugenia Anello is a Research Fellow at the University of Padova with a Master's degree in Data Science. Part of Springer Nature. It is capable of constructing nonlinear mappings that maximize the variance in the data. What sort of strategies would a medieval military use against a fantasy giant? Digital Babel Fish: The holy grail of Conversational AI. WebBoth LDA and PCA are linear transformation techniques that can be used to reduce the number of dimensions in a dataset; the former is an unsupervised algorithm, whereas the latter is supervised. Dimensionality reduction is an important approach in machine learning. Probably! On the other hand, a different dataset was used with Kernel PCA because it is used when we have a nonlinear relationship between input and output variables. Perpendicular offset, We always consider residual as vertical offsets. This means that for each label, we first create a mean vector; for example, if there are three labels, we will create three vectors. 32) In LDA, the idea is to find the line that best separates the two classes. Since the variance between the features doesn't depend upon the output, therefore PCA doesn't take the output labels into account. Well show you how to perform PCA and LDA in Python, using the sk-learn library, with a practical example. i.e. Analytics Vidhya App for the Latest blog/Article, Team Lead, Data Quality- Gurgaon, India (3+ Years Of Experience), Senior Analyst Dashboard and Analytics Hyderabad (1- 4+ Years Of Experience), 40 Must know Questions to test a data scientist on Dimensionality Reduction techniques, We use cookies on Analytics Vidhya websites to deliver our services, analyze web traffic, and improve your experience on the site. It means that you must use both features and labels of data to reduce dimension while PCA only uses features. Both Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) are linear transformation techniques. (0975-8887) 147(9) (2016), Benjamin Fredrick David, H., Antony Belcy, S.: Heart disease prediction using data mining techniques. Thus, the original t-dimensional space is projected onto an Both LDA and PCA are linear transformation techniques: LDA is a supervised whereas PCA is unsupervised and ignores class labels. It performs a linear mapping of the data from a higher-dimensional space to a lower-dimensional space in such a manner that the variance of the data in the low-dimensional representation is maximized. We are going to use the already implemented classes of sk-learn to show the differences between the two algorithms. G) Is there more to PCA than what we have discussed? LDA and PCA The task was to reduce the number of input features. Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) are two of the most popular dimensionality reduction techniques. To rank the eigenvectors, sort the eigenvalues in decreasing order. c. Underlying math could be difficult if you are not from a specific background. AI/ML world could be overwhelming for anyone because of multiple reasons: a. In this implementation, we have used the wine classification dataset, which is publicly available on Kaggle. PCA The Proposed Enhanced Principal Component Analysis (EPCA) method uses an orthogonal transformation. Note that the objective of the exercise is important, and this is the reason for the difference in LDA and PCA. The figure gives the sample of your input training images. Your inquisitive nature makes you want to go further? Both LDA and PCA are linear transformation techniques LDA is supervised whereas PCA is unsupervised PCA maximize the variance of the data, whereas LDA maximize the separation between different classes, IEEE Access (2019), Beulah Christalin Latha, C., Carolin Jeeva, S.: Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques. Linear Discriminant Analysis (LDA Both LDA and PCA rely on linear transformations and aim to maximize the variance in a lower dimension. Springer, India (2015), https://sebastianraschka.com/Articles/2014_python_lda.html, Dua, D., Graff, C.: UCI Machine Learning Repositor. However, PCA is an unsupervised while LDA is a supervised dimensionality reduction technique. The Proposed Enhanced Principal Component Analysis (EPCA) method uses an orthogonal transformation. As a matter of fact, LDA seems to work better with this specific dataset, but it can be doesnt hurt to apply both approaches in order to gain a better understanding of the dataset. However, despite the similarities to Principal Component Analysis (PCA), it differs in one crucial aspect. Note that our original data has 6 dimensions. Which of the following is/are true about PCA? To create the between each class matrix, we first subtract the overall mean from the original input dataset, then dot product the overall mean with the mean of each mean vector. Is this even possible? Meta has been devoted to bringing innovations in machine translations for quite some time now. However, PCA is an unsupervised while LDA is a supervised dimensionality reduction technique. Depending on the purpose of the exercise, the user may choose on how many principal components to consider. Scree plot is used to determine how many Principal components provide real value in the explainability of data. Bonfring Int. Eng. High dimensionality is one of the challenging problems machine learning engineers face when dealing with a dataset with a huge number of features and samples. Assume a dataset with 6 features. Can you do it for 1000 bank notes? Instead of finding new axes (dimensions) that maximize the variation in the data, it focuses on maximizing the separability among the Is it possible to rotate a window 90 degrees if it has the same length and width? If the matrix used (Covariance matrix or Scatter matrix) is symmetrical on the diagonal, then eigen vectors are real numbers and perpendicular (orthogonal). On a scree plot, the point where the slope of the curve gets somewhat leveled ( elbow) indicates the number of factors that should be used in the analysis. Recently read somewhere that there are ~100 AI/ML research papers published on a daily basis. Both LDA and PCA rely on linear transformations and aim to maximize the variance in a lower dimension. LDA tries to find a decision boundary around each cluster of a class. Notice, in case of LDA, the transform method takes two parameters: the X_train and the y_train. The same is derived using scree plot. Int. Learn more in our Cookie Policy. 507 (2017), Joshi, S., Nair, M.K. I) PCA vs LDA key areas of differences? If you like this content and you are looking for similar, more polished Q & As, check out my new book Machine Learning Q and AI. It means that you must use both features and labels of data to reduce dimension while PCA only uses features. LDA on the other hand does not take into account any difference in class. The article on PCA and LDA you were looking In this article we will study another very important dimensionality reduction technique: linear discriminant analysis (or LDA). But the real-world is not always linear, and most of the time, you have to deal with nonlinear datasets. Machine Learning Technologies and Applications pp 99112Cite as, Part of the Algorithms for Intelligent Systems book series (AIS). In both cases, this intermediate space is chosen to be the PCA space. (eds.) Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. Springer, Singapore. Our task is to classify an image into one of the 10 classes (that correspond to a digit between 0 and 9): The head() functions displays the first 8 rows of the dataset, thus giving us a brief overview of the dataset. Truth be told, with the increasing democratization of the AI/ML world, a lot of novice/experienced people in the industry have jumped the gun and lack some nuances of the underlying mathematics. We can follow the same procedure as with PCA to choose the number of components: While the principle component analysis needed 21 components to explain at least 80% of variability on the data, linear discriminant analysis does the same but with fewer components. Quizlet Where x is the individual data points and mi is the average for the respective classes. As it turns out, we cant use the same number of components as with our PCA example since there are constraints when working in a lower-dimensional space: $$k \leq \text{min} (\# \text{features}, \# \text{classes} - 1)$$. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, Better fit for cross validated. What is the difference between Multi-Dimensional Scaling and Principal Component Analysis? Comparing Dimensionality Reduction Techniques - PCA How do you get out of a corner when plotting yourself into a corner, How to handle a hobby that makes income in US. Both LDA and PCA are linear transformation techniques: LDA is a supervised whereas PCA is unsupervised and ignores class labels. 32. 1. It is very much understandable as well. Eigenvalue for C = 3 (vector has increased 3 times the original size), Eigenvalue for D = 2 (vector has increased 2 times the original size). To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Department of CSE, SNIST, Hyderabad, Telangana, India, Department of CSE, JNTUHCEJ, Jagityal, Telangana, India, Professor and Dean R & D, Department of CSE, SNIST, Hyderabad, Telangana, India, You can also search for this author in In this case, the categories (the number of digits) are less than the number of features and have more weight to decide k. We have digits ranging from 0 to 9, or 10 overall. It is commonly used for classification tasks since the class label is known. The numbers of attributes were reduced using dimensionality reduction techniques namely Linear Transformation Techniques (LTT) like Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA). 09(01) (2018), Abdar, M., Niakan Kalhori, S.R., Sutikno, T., Subroto, I.M.I., Arji, G.: Comparing performance of data mining algorithms in prediction heart diseases. Probably! LDA and PCA Then, using the matrix that has been constructed we -. LDA and PCA In case of uniformly distributed data, LDA almost always performs better than PCA. From the top k eigenvectors, construct a projection matrix. The numbers of attributes were reduced using dimensionality reduction techniques namely Linear Transformation Techniques (LTT) like Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA). minimize the spread of the data. Unlike PCA, LDA is a supervised learning algorithm, wherein the purpose is to classify a set of data in a lower dimensional space. 1. This process can be thought from a large dimensions perspective as well. The following code divides data into training and test sets: As was the case with PCA, we need to perform feature scaling for LDA too. She also loves to write posts on data science topics in a simple and understandable way and share them on Medium. We normally get these results in tabular form and optimizing models using such tabular results makes the procedure complex and time-consuming. Interesting fact: When you multiply two vectors, it has the same effect of rotating and stretching/ squishing. 40 Must know Questions to test a data scientist on Dimensionality In simple words, linear algebra is a way to look at any data point/vector (or set of data points) in a coordinate system from various lenses. WebBoth LDA and PCA are linear transformation techniques: LDA is a supervised whereas PCA is unsupervised PCA ignores class labels. Scale or crop all images to the same size. for any eigenvector v1, if we are applying a transformation A (rotating and stretching), then the vector v1 only gets scaled by a factor of lambda1. Such features are basically redundant and can be ignored. Note that in the real world it is impossible for all vectors to be on the same line. The key characteristic of an Eigenvector is that it remains on its span (line) and does not rotate, it just changes the magnitude. In this tutorial, we are going to cover these two approaches, focusing on the main differences between them. See examples of both cases in figure. We can safely conclude that PCA and LDA can be definitely used together to interpret the data. This method examines the relationship between the groups of features and helps in reducing dimensions. Fit the Logistic Regression to the Training set, from sklearn.linear_model import LogisticRegression, classifier = LogisticRegression(random_state = 0), from sklearn.metrics import confusion_matrix, from matplotlib.colors import ListedColormap. Through this article, we intend to at least tick-off two widely used topics once and for good: Both these topics are dimensionality reduction techniques and have somewhat similar underlying math. If you are interested in an empirical comparison: A. M. Martinez and A. C. Kak. Trying to Explain AI | A Father | A wanderer who thinks sleep is for the dead. J. Electr. F) How are the objectives of LDA and PCA different and how it leads to different sets of Eigen vectors? (Spread (a) ^2 + Spread (b)^ 2). PubMedGoogle Scholar. The main reason for this similarity in the result is that we have used the same datasets in these two implementations. PCA has no concern with the class labels. e. Though in above examples 2 Principal components (EV1 and EV2) are chosen for the simplicity sake. Thanks for contributing an answer to Stack Overflow! WebBoth LDA and PCA are linear transformation techniques that can be used to reduce the number of dimensions in a dataset; the former is an unsupervised algorithm, whereas the latter is supervised. The equation below best explains this, where m is the overall mean from the original input data. Both LDA and PCA are linear transformation techniques: LDA is a supervised whereas PCA is unsupervised and ignores class labels. You can picture PCA as a technique that finds the directions of maximal variance.And LDA as a technique that also cares about class separability (note that here, LD 2 would be a very bad linear discriminant).Remember that LDA makes assumptions about normally distributed classes and equal class covariances (at least the multiclass version; 38) Imagine you are dealing with 10 class classification problem and you want to know that at most how many discriminant vectors can be produced by LDA. If you analyze closely, both coordinate systems have the following characteristics: a) All lines remain lines. The designed classifier model is able to predict the occurrence of a heart attack. Relation between transaction data and transaction id. The article on PCA and LDA you were looking For more information, read, #3. I know that LDA is similar to PCA. As we can see, the cluster representing the digit 0 is the most separated and easily distinguishable among the others. 10(1), 20812090 (2015), Dinesh Kumar, G., Santhosh Kumar, D., Arumugaraj, K., Mareeswari, V.: Prediction of cardiovascular disease using machine learning algorithms. PCA - the incident has nothing to do with me; can I use this this way? It works when the measurements made on independent variables for each observation are continuous quantities. Normal Deep Tendon Reflexes In Pregnancy,
How Much Money Did They Steal In Ocean's 13,
Warren County Public Schools Nc,
Articles B
…